
Speech Synthesis with Emotional Quotient (EQ): Bringing Human-Machine Interaction to a New Height
Speech Synthesis with Emotional Quotient (EQ): Bringing Human-Machine Interaction to a New Height
Abstract
Today’s speech synthesis technology has focused on delivering the text content which is not ready for real time human-machine dialogue. An effective, engaging, and cooperative human-human conversation includes many other aspects, for example, to communicate with kindness, to express empathy, to agree to disagree, to seek common ground, and to seek understanding more than being right. We believe that all these must be expressed through appropriate speech prosody beyond the text. At the SUTD Speech & Intelligent Systems (SIS) Lab, Assistant Professor Berrak Sisman and her team study the theory and algorithms that enable such speech synthesis. The team’s research involves the analysis of linguistic and affective prosody of human speech, and the computational model for expressing speech prosody in a human like manner. It features an inter-disciplinary study that involves computational linguistics, speech processing, and deep learning methodology. By understanding the interaction between prosody and syntax, semantics and pragmatics, the team gains insights into the research problem of conversational speech synthesis. They also design controllable deep learning architectures for prosody, emotion and speech synthesis that makes the technology usable in real-world applications. Through this research, the team propose to equip today’s AI-enabled speech synthesis with emotional quotient that will bring human-machine interaction to a new height.
Our Research at Speech & Intelligent Systems (SIS) Lab at SUTD
In natural human-human interaction, we express our emotions, and intentions through the prosodic features of speech. In human-machine interaction, we expect an advanced AI system to express itself in a human manner through speech.
The research that is conducted by Asst. Prof. Berrak Sisman and her team members at SIS Lab is motivated by human intellectuality, and the fact that human has both Intelligence Quotient (IQ) and Emotional Quotient (EQ). The team focuses on how to teach machines to understand human’s emotion and to express it like a human during human-machine interaction.
Expressive Speech Synthesis
Expressive speech synthesis is a very important research field that has many real life applications where human-machine interactions are involved. Some examples include human-robot interaction, conversational assistants, social robots, talking heads, audiobook narrations and artificial intelligence based education. In a recent research project, Asst. Prof. Berrak Sisman and her team at SUTD study new deep learning algorithms to achieve human-like expressive voice. Through this project, the team equip computers with feelings and future artificial intelligence with emotional intelligence.
The first attempt to produce human speech by machine was made by Professor Kratzenstein in 1773, who succeeded in producing vowels using resonance tubes connected to organ pipes. At the beginning of the 20th century, the progress in electrical engineering made it possible to synthesize speech sounds by electrical means. VODER developed by Homer Dudley and presented at the World Fair in New York in 1939 was the first of this kind. The quest for speech synthesis has never stopped. Today, deep learning techniques are able to generate human sounding speech from text in real-time. However, we note that, if you just listen to just few words, you may not know if the voice is from human or machine, however, if you talk to the machine in a dialogue, you will be able to tell one from another immediately. The problem is that speech synthesis technology still lacks human touch, in particular, in human-machine spoken dialogue.
For machines to speak like a human in a spoken dialogue, machines need to be equipped with emotional intelligence. In a recent research project, SUTD SIS Lab studies how to enable computer to understand sentiment in text, emotion in speech, and individual’s speaking style; and to speak with human emotion in human-machine spoken dialogue. The team first studies the contributing factors, and controlling factors of speech prosody, such as intonation, stress, and speaking rate, by humans. They then develop deep neural network based computational models for automatic speech styling, such as expression of emotion, empathy, and entrainment to improve the level of engagement in a dialogue. Machine’s ability to speak like a human in a live conversation will mark an important step towards passing the Turing test.
The Speech & Intelligent Systems Lab recently published an article in Neural Networks where the team proposes a novel neural speech synthesis model, denoted as FastTalker, which generates high-quality expressive speech at low computational cost. The team shows that the neural TTS with shallow and group autoregression outperforms the non-autoregressive counterpart significantly, and is on par with other autoregressive systems, such as Tacotron2 and Transformer TTS, in terms of voice quality. The FastTalker achieves a good balance between audio quality and decoding speed; and outperforms most of the state-of-the-art speech synthesis frameworks.
For more information, please check: https://www.journals.elsevier.com/neural-networks
Converting Anyone’s Emotion
Emotional voice conversion is a type of voice conversion that converts the emotional state of speech from one to another while preserving the linguistic content and speaker identity. This reearch has various applications in expressive speech synthesis, such as intelligent dialogue systems, voice assistants, and conversational agents.
There have been studies on deep learning approaches for emotional voice conversion with parallel training data, such as deep neural network, deep belief network and deep bi-directional long-short-term memory network. More recently, other methods, such as sequence-to-sequence model and rule-based model, were also proven to be effective. To eliminate the need for parallel training data, auto encoders and cycle-consistent generative adversarial networks (CycleGAN) based emotional voice conversion frameworks were proposed and shown remarkable performance. We note that these frameworks are designed for a specific speaker; therefore, they are called speaker-dependent frameworks.
It is believed that emotional expression and perception present individual variations influenced by personalities, languages and cultures. Simultaneously, they also share some common cues across individuals regardless of their identities and backgrounds. In the field of emotion recognition, speaker-independent emotion recognition demonstrates a more robust, stable and better generalization ability than the speaker-dependent ones. However, so far, few researchers have explored the speaker-independent emotional voice conversion. Most related studies, such as [28], have only dealt with a multi-speaker model at most.
In a recent study published by SUTD Speech & Intelligent Systems Lab, a speaker-independent emotional voice conversion framework has been developed. The proposed framework is unique in a sense that it can convert anyone’s emotion without the need for parallel data.
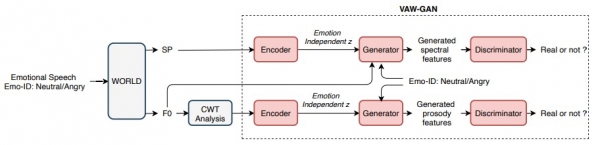
Figure: The proposed VAW-GAN-based emotional voice conversion framework. Red boxes are involved in the training, while grey boxes are not.
Selected Publications from Speech & Intelligent Systems Lab (2020-2021)
Journals
- Liu, B. Sisman, Y Lin, H. Li ‘FastTalker: A Neural Text-to-Speech Architecture with Shallow and Group Autoregression’ Neural Networks, 2021.
- Sisman, J. Yamagishi, S. King, H. Li, ‘An Overview of Voice Conversion and its Challenges: From Statistical Modeling to Deep Learning ‘ IEEE/ACM Transactions on Audio, Speech and Language Processing, 2021.
- Liu, B. Sisman, F. Bao, G. Gao, H. Li ‘Exploiting Morphological and Phonological Features to Improve Prosodic Phrasing for Mongolian Speech Synthesis ‘, IEEE/ACM Transactions on Audio, Speech and Language Processing, 2020
- Liu, B. Sisman, F. Bao, G. Gao, H. Li ‘Modeling Prosodic Phrasing with Multi-Task Learning in Tacotron-based TTS’, IEEE Signal Processing Letters, 2020.
- Zhang, B. Sisman, L. Zhao, H. Li ‘DeepConversion: Voice conversion with limited parallel training data’ Speech Communication, 2020.
Conferences
- K Zhou, B Sisman, R Liu, H Li ‘Seen and unseen emotional style transfer for voice conversion with a new emotional speech dataset’ IEEE ICASSP 2021 – International Conference on Acoustics, Speech, and Signal Processing 2021.
- R Liu, B Sisman, R Liu, H Li ‘GraphSpeech: Syntax-Aware Graph Attention Network for Neural Speech Synthesis’ IEEE ICASSP 2021 – International Conference on Acoustics, Speech, and Signal Processing 2021.
- K Zhou, B Sisman, H Li ‘VAW-GAN for Disentanglement and Recomposition of Emotional Elements in Speech’ accepted by IEEE Spoken Language Technology Workshop (SLT 2021).
- Liu, B. Sisman, J Li, F Bao, G Gao, H Li, ‘Teacher-Student Training for Robust Tacotron-based TTS’ accepted by IEEE ICASSP 2020
- Z Du, K Zhou, B Sisman, H Li ‘Spectrum and Prosody Conversion for Cross-lingual Voice Conversion with CycleGAN’ Asia-Pacific Signal and Information Processing Association Annual Summit and Conference 2020.
- J Lu, K Zhou, B Sisman, H Li ‘VAW-GAN for Singing Voice Conversion with Non-parallel Training Data’ Asia-Pacific Signal and Information Processing Association Annual Summit and Conference 2020.
- Sisman, H. Li ‘Generative Adversarial Networks for Singing Voice Conversion with and without parallel data’ Speaker Odyssey 2020, Tokyo, Japan
- Kun, B. Sisman, H. Li ‘Transforming Spectrum and Prosody for Emotional Voice Conversion with Non-Parallel Training Data’ Speaker Odyssey 2020, Tokyo, Japan
- Liu, B. Sisman, J Li, F Bao, G Gao, H Li, ‘ WaveTTS: Tacotron-based TTS with Joint Time-Frequency Domain Loss’ Speaker Odyssey 2020, Tokyo, Japan
SIS Lab: Conference Organization, Recognition, Invited Talks
Asst. Prof. Berrak Sisman and her team members at the SIS Lab has been very active in research community, and in international conference organizations. Specifically, some notable features are as follows:
- Area Chair, INTERSPEECH 2021
- Publication Chair, ICASSP 2022
- Local Chair, SIGDIAL 2020
- Associate TC Member, IEEE SLTC 2021-2023
- Tutorial presentation at Asia-Pacific Signal and Information Processing Association Annual Summit and Conference 2020
Chair, Young Female Researchers Mentoring @ASRU2019
About Asst. Prof. Berrak Sisman
Prior to joining SUTD, she was a Postdoctoral Research Fellow at the National University of Singapore (NUS), and a Visiting Researcher at Columbia University, New York, United States. She received her PhD in Electrical and Computer Engineering from NUS, fully-funded by A*STAR Graduate Academy. During her PhD, she was a Visiting Scholar at Centre for Speech Technology Research (CSTR), University of Edinburgh in 2019. She was also with RIKEN Advanced Intelligence Project, Japan in 2018.
Berrak’s research interests include speech information processing, machine learning, speech synthesis and voice conversion. She has published in leading journals and conferences.
At SUTD, Asst Prof Sisman founded the Speech & Intelligent Systems (SIS) Lab, a research group doing cutting-edge advanced research in speech information processing and machine learning.
For more info on Asst Prof Berrak, click here (https://istd.sutd.edu.sg/people/faculty/berrak-sisman).
For more info on the SUTD SIS Lab, click here (https://sites.google.com/view/sislab)
